Toward a Baseline for Khmer OCR
An Exploration of Low-Resource, Non-Latin Optical Character Recognition using CNN + Transformer Architecture
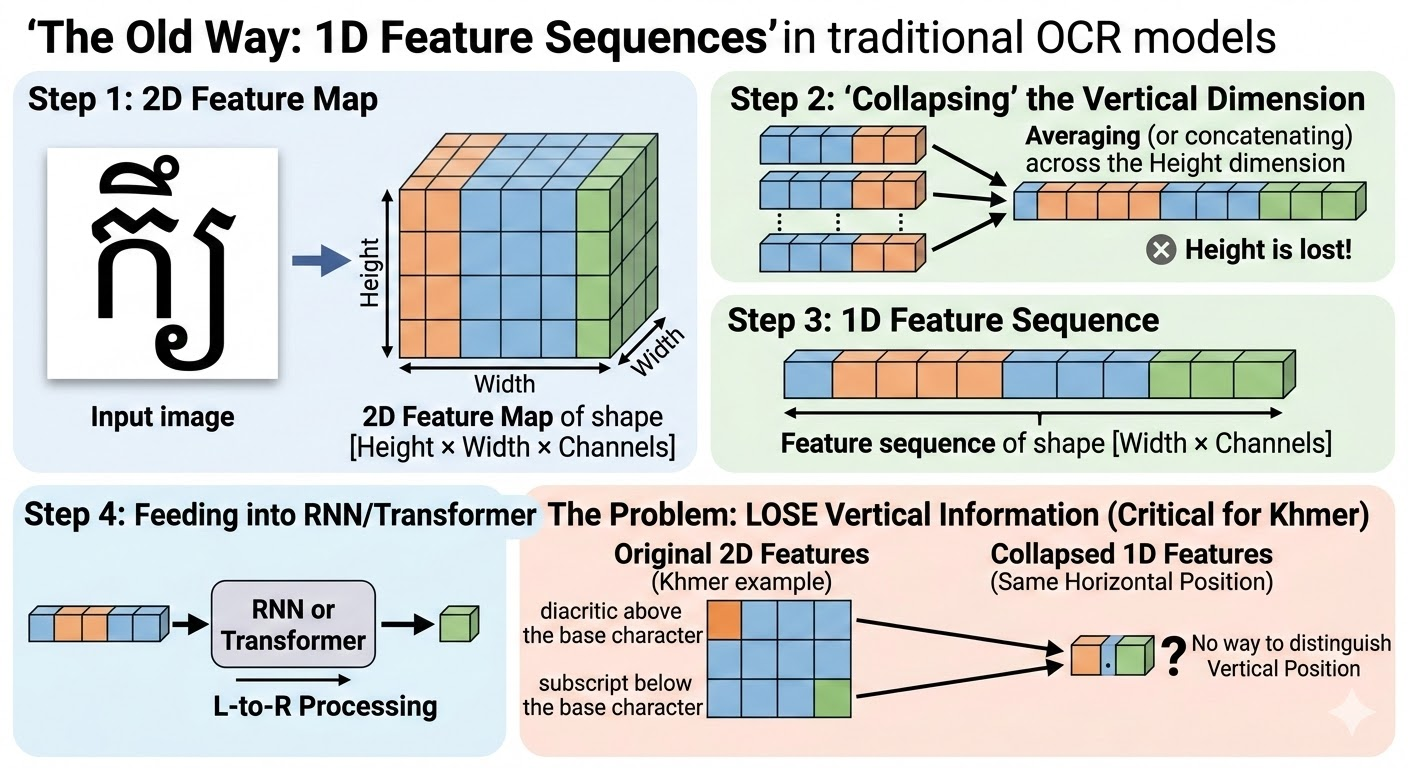
Why can't existing tools read Khmer?
Complex Script
Characters stack vertically — above, below, and beside each other. Left-to-right OCR misses them entirely.
Long Text Lines
No word spaces means sentences are one huge image. Resizing to fit crushes the tiny stacked characters.
Scarce Data
Very few labeled Khmer text examples exist. AI needs millions of samples — Khmer has far less.
A purpose-built AI that reads Khmer in two dimensions
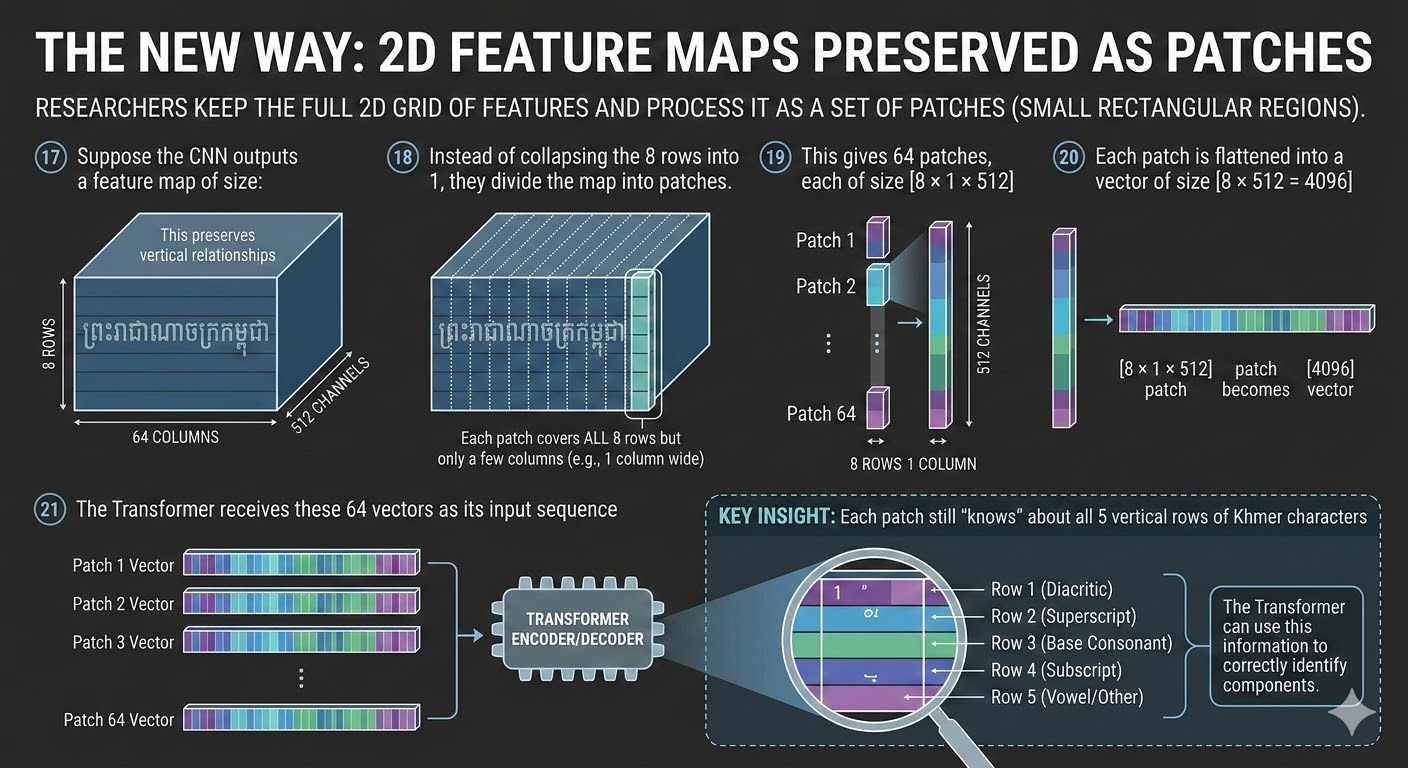
2D Vision
Scans images both left-right and up-down — capturing stacked vowels and subscripts that 1D tools miss.
Image Slicing
Cuts long sentences into overlapping pieces, processes each at full quality, then merges the results.
Synthetic Data
2.8 million computer-generated Khmer training images from real fonts — solving the data scarcity problem.
Transfer to 5 Scripts
After Khmer, the model was rapidly adapted to Thai, Lao, Burmese, Vietnamese, and Hindi.
How the system reads Khmer
Input Image
Photo or scan of a Khmer text line
CNN Features
Vision scanner captures shapes in height and width
Patch Encoder
Image split into grid patches, each tagged
Transformer Enc & Dec
Encoder learns context, decoder outputs characters
Slice. Process. Merge.
Resize the entire image to a fixed width.
Tiny stacked characters get crushed — the AI cannot read them. Also very slow to process one giant image.
Slice into overlapping sections — P1, P2, P3, P4.
Each piece is processed at full quality. Small characters stay sharp and readable. Results merged at the end — up to 2× faster.
Did it work?
Reduction in character mistakes vs. standard Tesseract OCR on real Khmer ID cards.
Khmer model adapted to Thai, Lao, Burmese, Vietnamese, and Hindi with minimal extra training.
Reading in both height and width consistently outperforms left-to-right-only models in 4 of 5 test categories.